
|
|

|
So hey, I’m Dan McKinley, I’m visiting you from Los Angeles |

|
I was an early employee at Etsy and worked there for seven years. I’ve worked for Stripe since, and I cofounded a continuous delivery platform company. |

|
Along the way I’ve talked to a lot of companies that have been interested in continuous delivery. |

|
After I left Etsy, I had this notion that you could take the tools that we used there and just drop them into another company to get it onto the golden path. |

|
But my experience has been that that’s not the case at all. I think one of our mistakes when talking about continuous delivery, at Etsy anyway, was to talk with an emphasis on the tools. |

|
Continuous delivery is not a set of tools you can buy or fork, or at least it’s not just that. I think all of this work was really important to give the movement credibility. But, I think we failed to communicate clearly what what it was like to live within the system, and what it was like to keep it working. I wanted to address that with this talk. |

|
One of the key things that made the system work was that we really were trying to get the most out of every engineer we had. |

|
And we were working backwards from the goals of changing a lot of stuff, and doing it safely. |

|
And as we scaled up, we tried really hard not to give up on the idea that everyone had a stake in fixing production when it was broken. |

|
I haven’t seen a lot of material about how you actually go about organizing high numbers of safe deploys every day. |

|
It turns out that this is really more of a human orchestration problem than it is a technical problem. So it may be less straightforward than a rant about rsync, but I’m going to try to do it. |

|
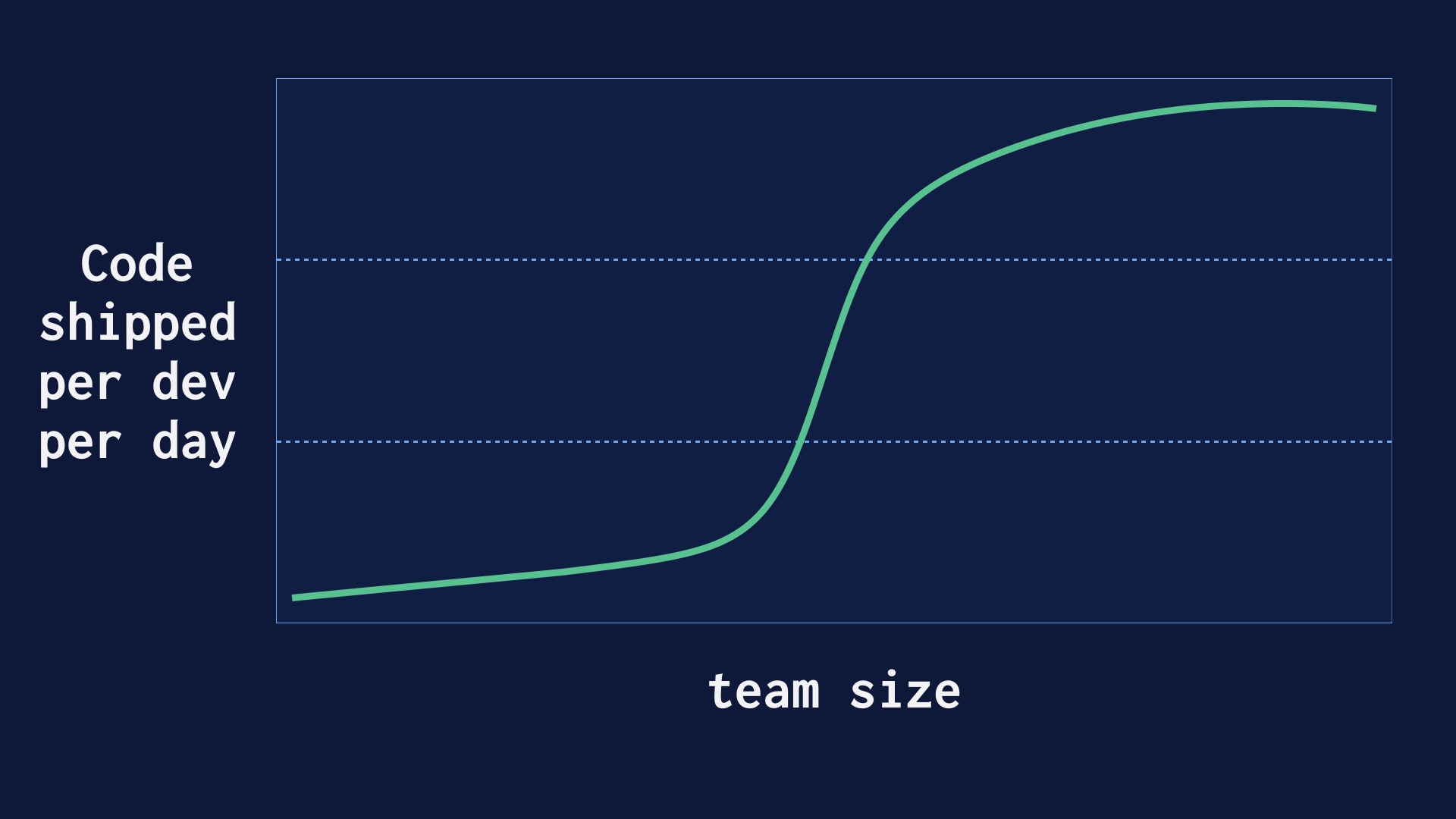
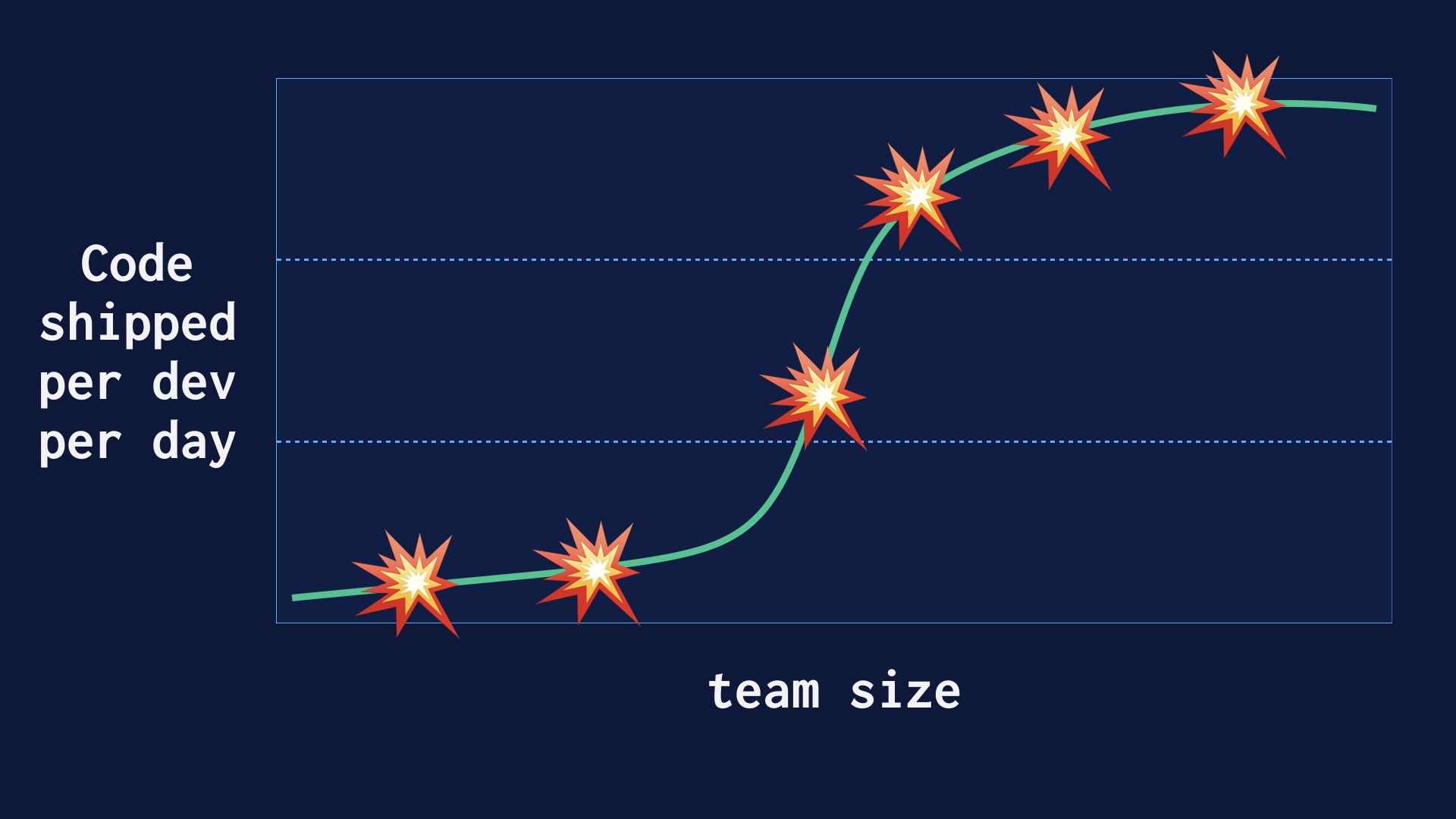
How do you even get to the point of deploying 40 or 60 times a day? |
|
We got there on purpose, at the same time we were growing as an organization. We believed that deploying as often as possible would lead to safety and development velocity, and I think we were vindicated in that. But ramping that up wasn’t immediate. It went like this. |
|
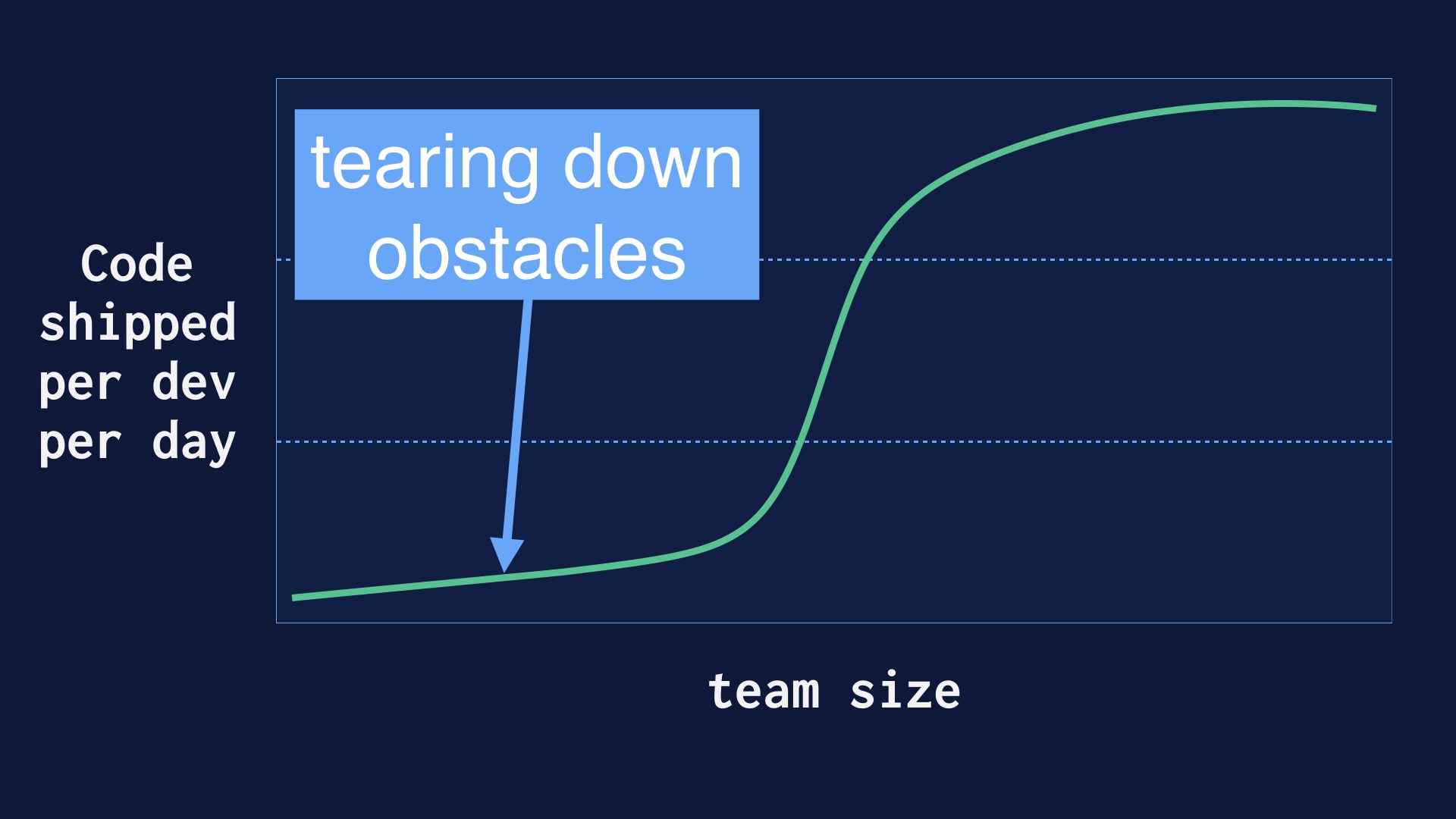
Our company wasn’t conceived as a continuous delivery engineering organization. Pretty much the opposite actually. So when we decided we were going to aim for deploying many times a day, there was a lot of pre-existing process that had to be destroyed. I’ll talk about some of that. |
|
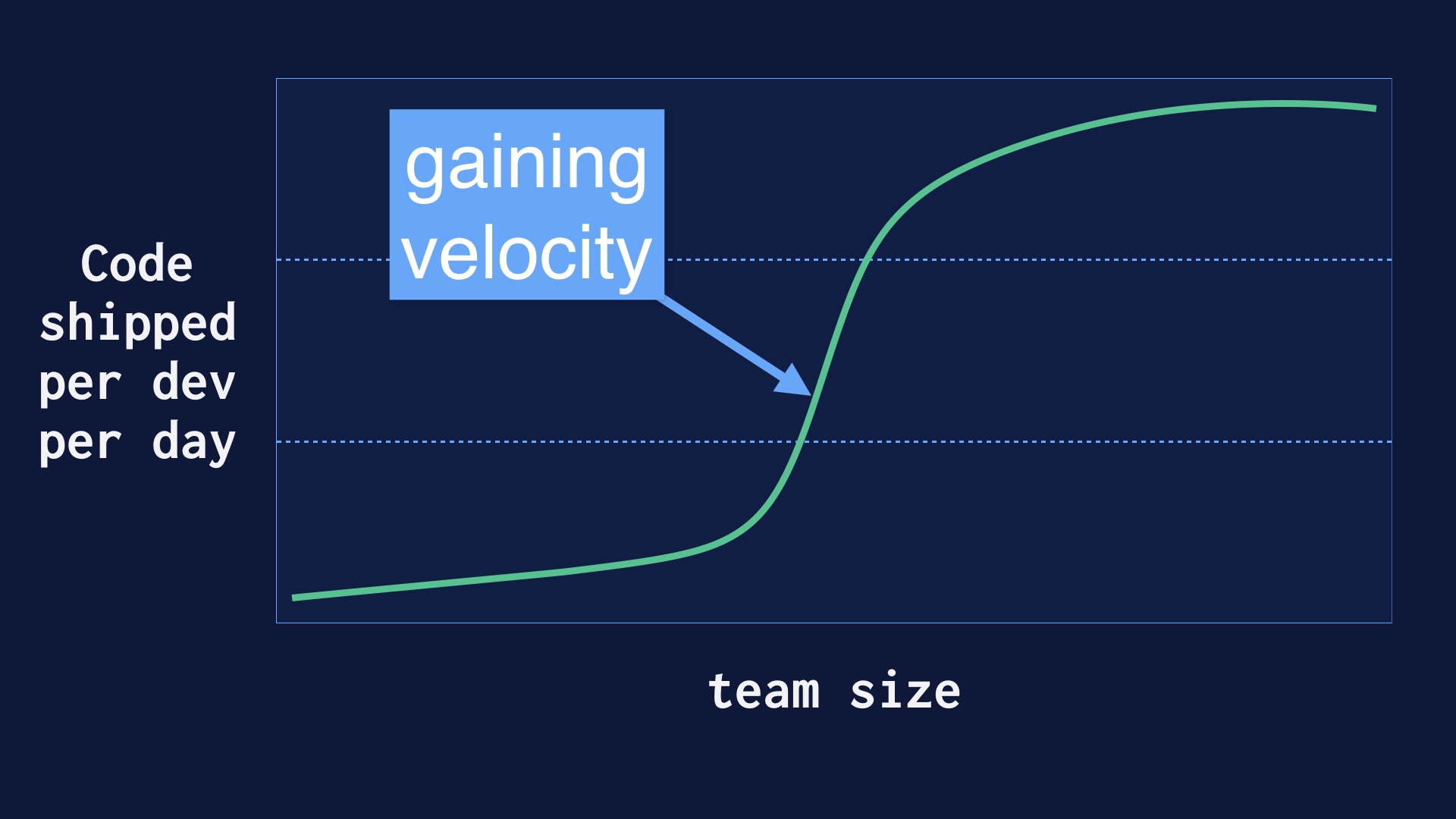
After that there was a middle epoch where improved our process rapidly, and got a lot more deploys per day very quickly. |

|
But as we were doing this our engineering team grew from a few dozen folks up to well over a hundred. And it’s nontrivial to go from a handful of people deploying 40 times a day up to a hundred people deploying 40 times per day. |
|
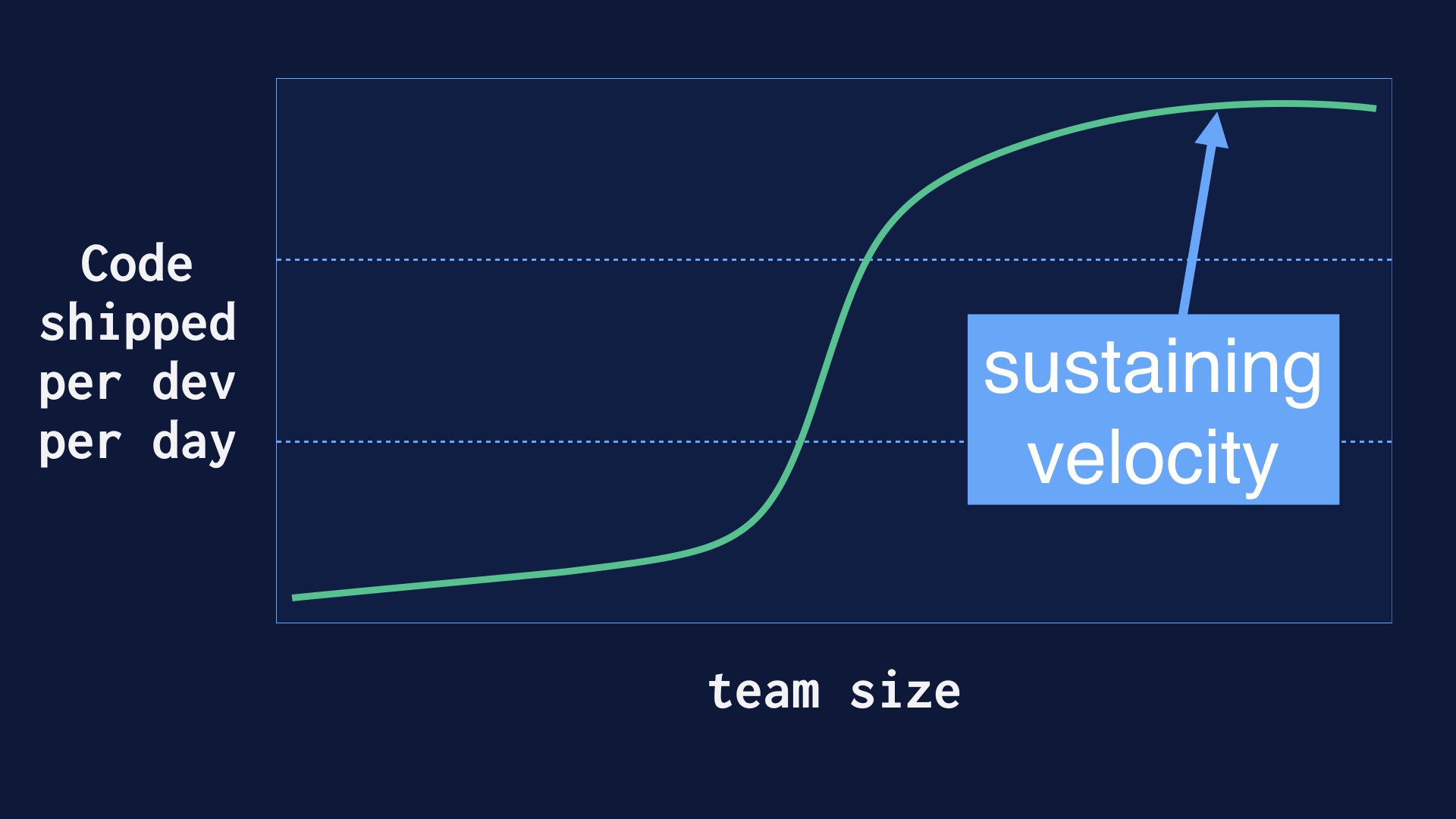
A great deal of effort went into sustaining that velocity once we had it. |
|
We had a lot of places along the way where there were challenges or the process broke down entirely. With this talk I wanted to put together a narrative of how we fought through some of the key problems we had. |

|
I was with the company up until we had about 150 people deploying regularly. |

|
Beyond that I imagine you may need different things. |
|
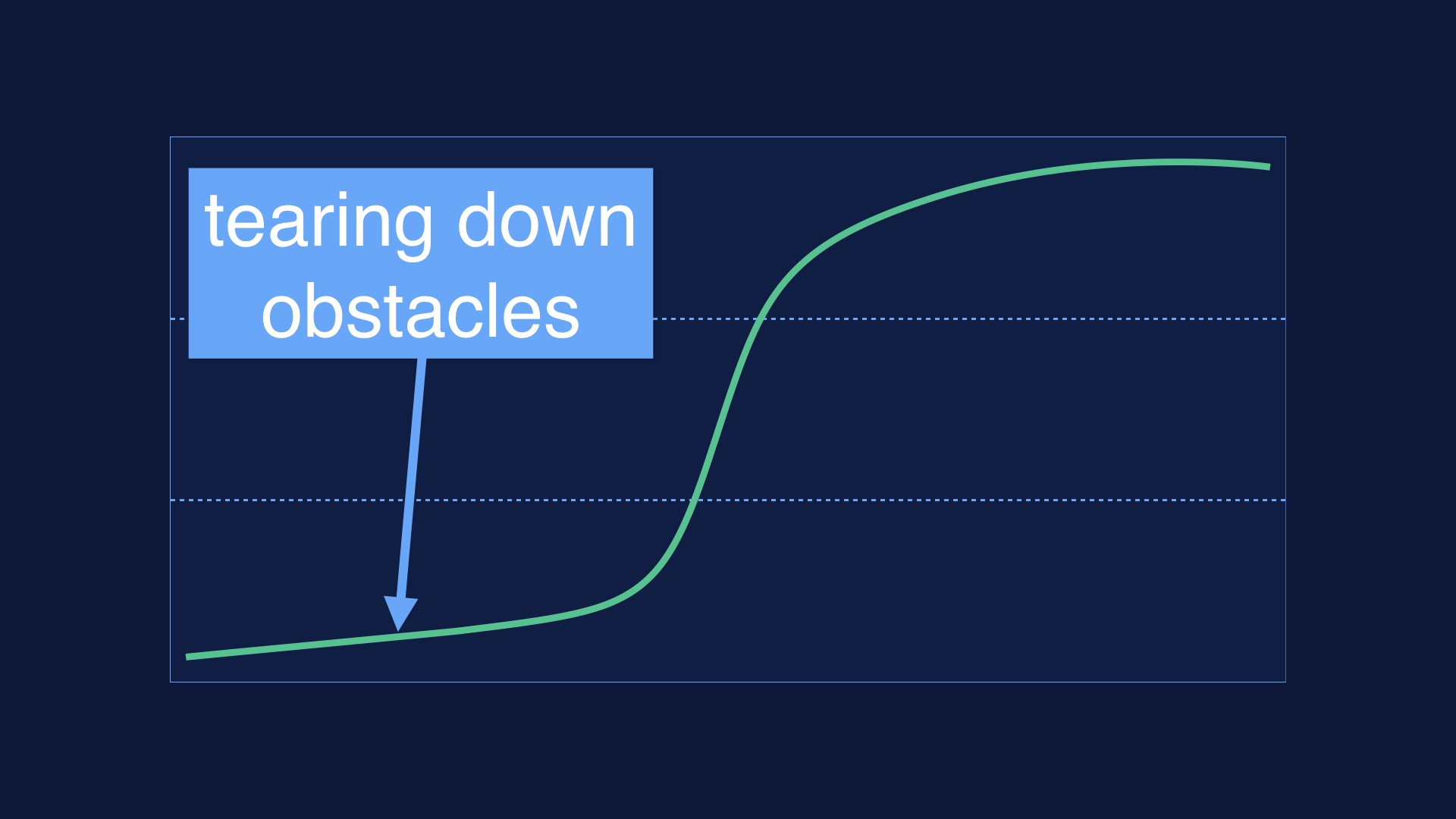
Ok so like I said, we had to destroy some process to get started. |

|
Namely, we had a lot of process that was prophylactic. It was built with the intent of finding production problems before product |

|
Let me tell you a quick story. In 2008, Etsy’s engineering founders parted ways with the company. And those folks meant well, but they had been gatekeeping production pretty hard. We had not really been able to touch the site, and now we were about to expected to. There was also no production monitoring to speak of. We suddenly found ourselves out to sea. |

|
My reaction to this was to start writing some integration tests. Using selenium, that web driver toolkit zenefits used to break the law. That seemed sensible as a way have at least a modicum of safety as started changing things. It was also nice that this was a proactive thing I could do with literally nobody helping me. |
|
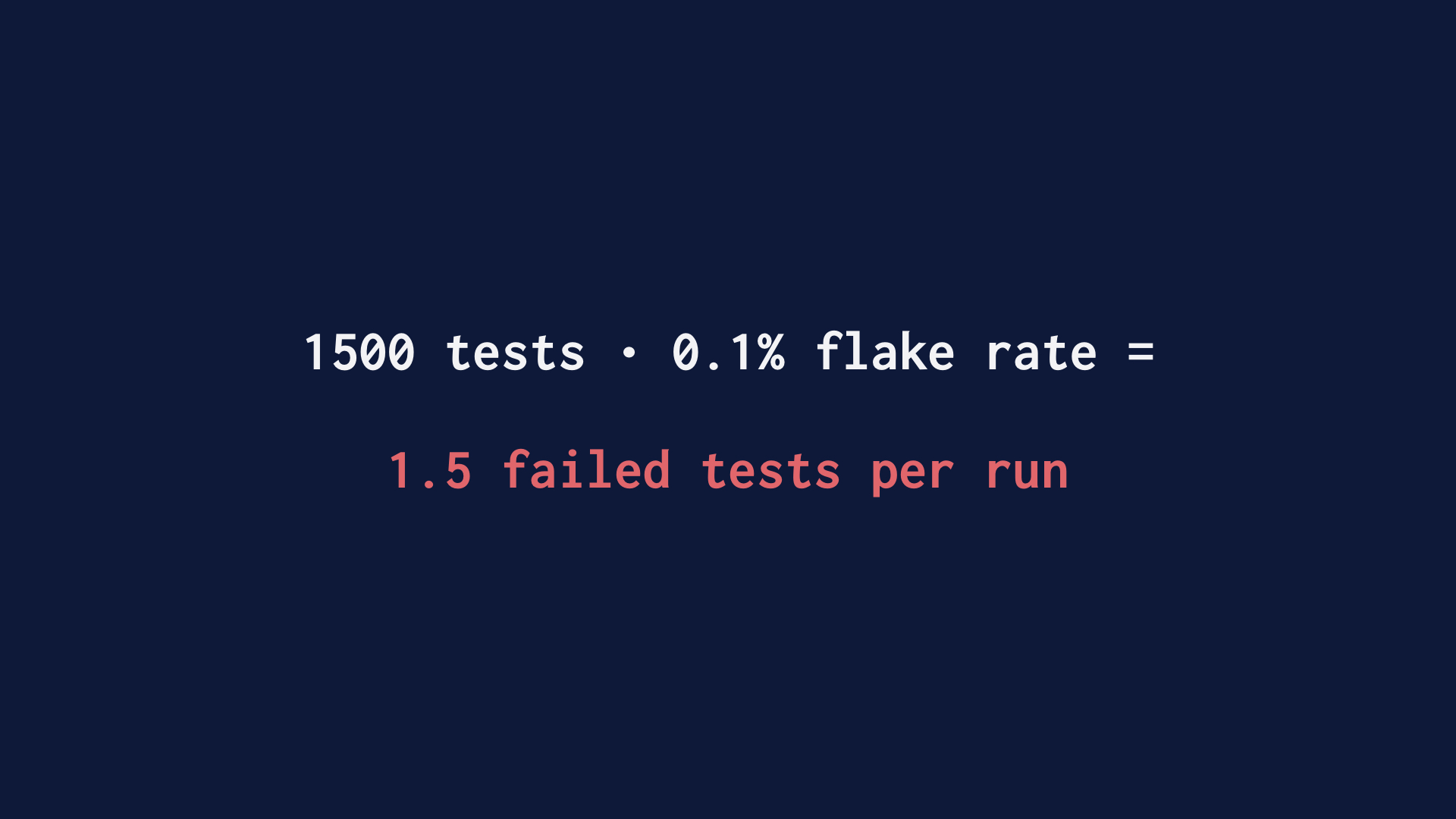
The thing you should know about writing web-driving integration tests is that doing this well is at least as hard as writing a multithreaded program. And that’s a domain where human competence isn’t estimated to be high. The other problem with testing across process boundaries is that failure is a thing that can’t be entirely avoided. So what you tend to wind up with there is a lot of tests that work most of the time. Even if you’re really good and prevent most race conditions, you’re still going to have some defects. Given enough tests, that means that one is always failed. |

|
We solved that by deleting all 1500 tests, representing several human years of effort. |

|
We went back to the drawing board here. We realized that the whole point of tests is to gain confidence before changing things. And to the extent that there are false negatives in the tests, or the tests gum up the works, they’re doing the opposite of that. Tests are one way to gain some confidence that a change is safe. But that’s all they are. Just one way. |
|
Ramping up code very gradually in production is another way |
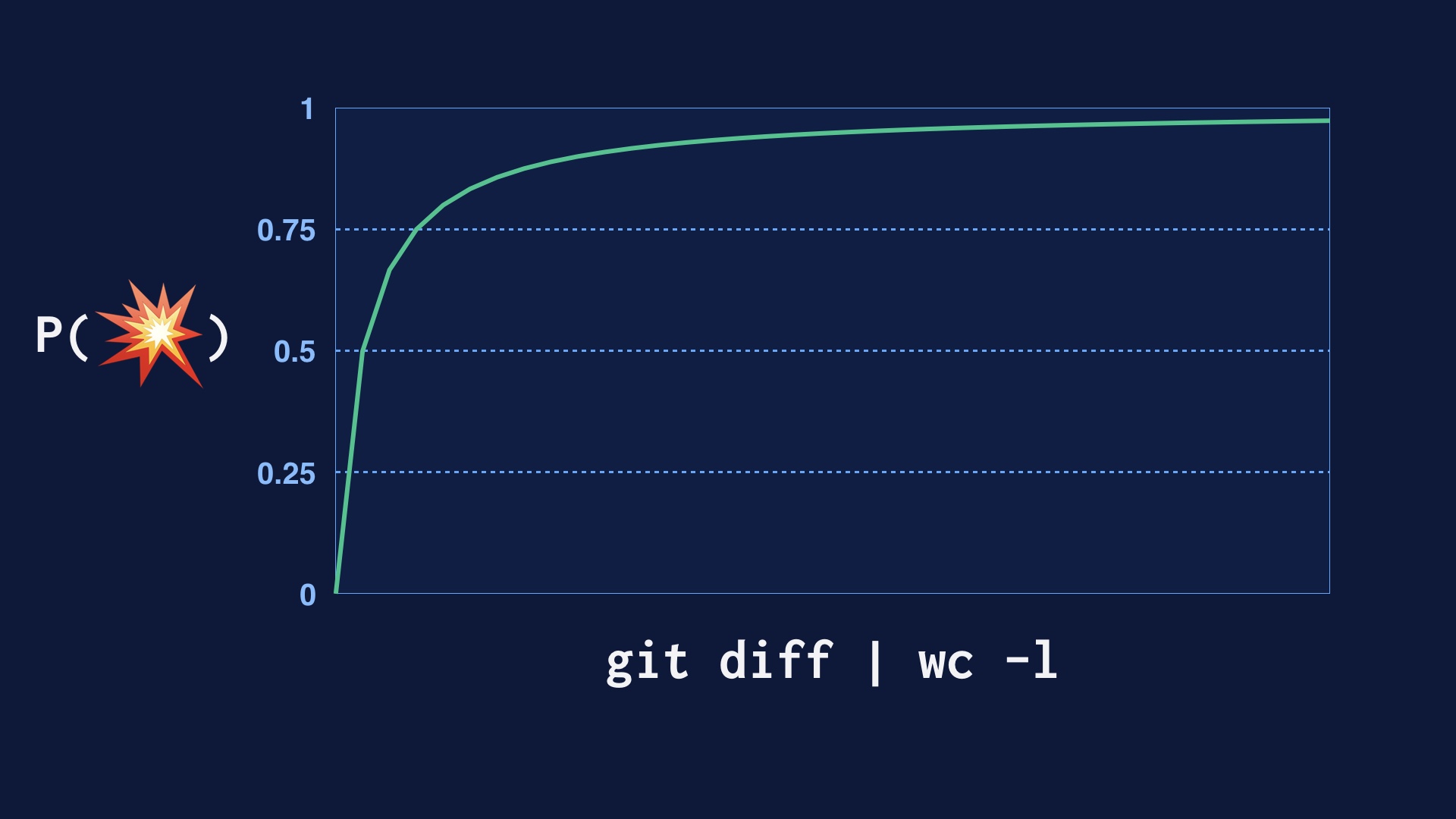
|
Deploying code in smaller and smaller pieces is another way. In abstract, every single line of code you deploy has some probability of breaking the site. So if you deploy a lot of lines of code at once, you’re just going break the site. And you stand a better chance of inspecting code for correctness the less of it there is. |
|
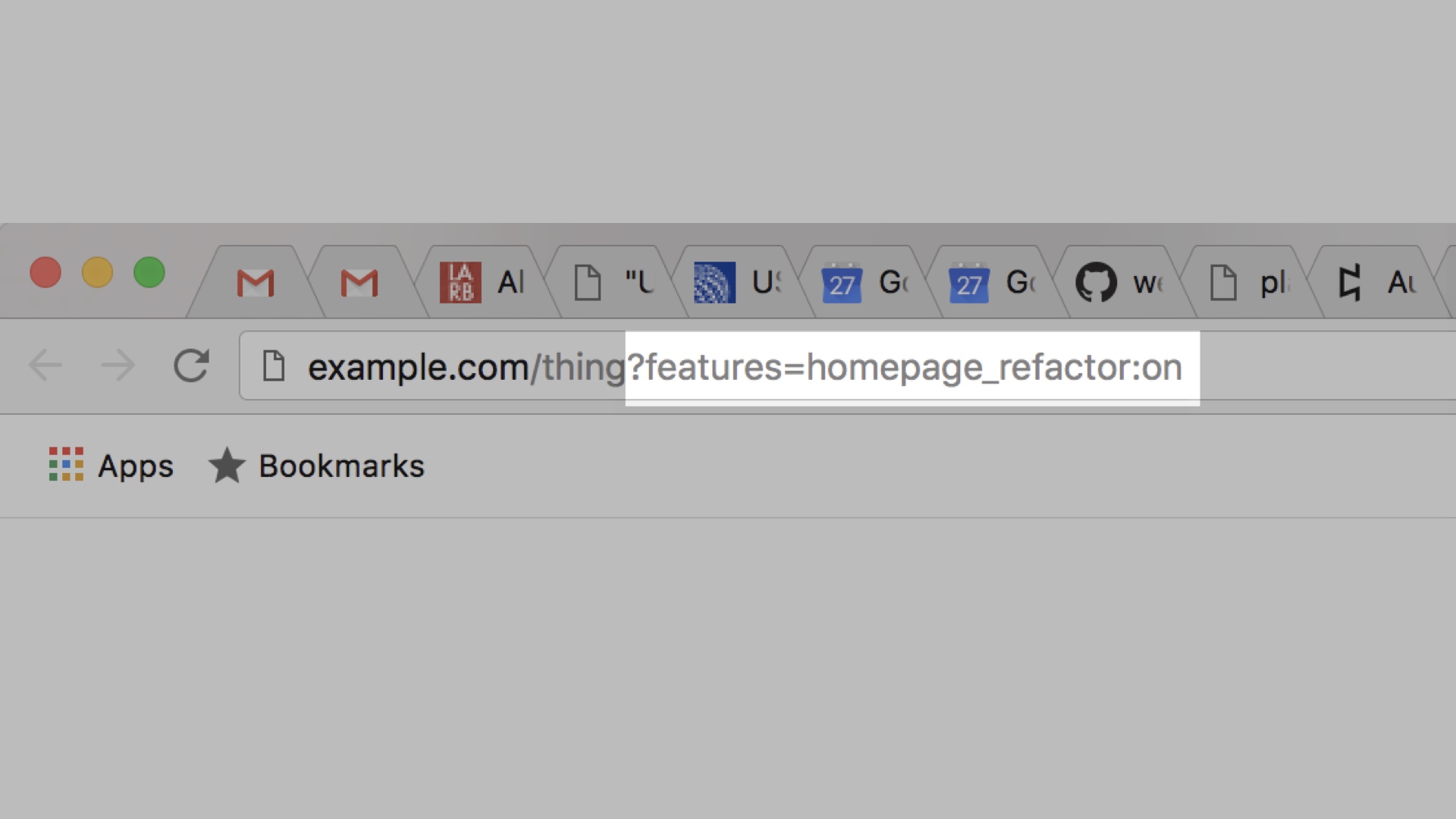
Deploying code so that users can’t see it and then using feature flags to test it in production is another good way to gain confidence. |

|
Over time we did write a lot more tests. Unit tests that finish quickly and don’t have false negatives are a really great confidence-builder. |

|
You may have tests, but you must have monitoring. You can write an infinite number of tests and only asymptotically approach zero problems in production. So at least when building a website, your priority should be knowing things are broken and having the capability to fix them as quickly as possible. Preventing problems is a distant second. |

|
Baroque source control rituals were another pre-existing thing we had that we had to give up on in order to ship code frequently. I’ll just summarize this by saying that git is bad. |
|
Git of course is not really bad. But it was created to support software that’s nothing at all like web software. The Linux kernel has many concurrent supported versions. A website, on the other hand, doesn’t really have a version at all. It has a current state. |
|
Github is likewise oriented around open source libraries, and it may be great for that, but there’s no reason to suspect that things you do there should work as well for building an online application. But the tendency among engineers is to start with Github, and all of the workflow and cultural baggage that surrounds it. Then they bang on stuff from there until something’s in production. |

|
We eventually came to a realization that there was no point to the rituals we were performing with revision control. It’s better to conceive of a website as a living organism where all of the versions of it are all jumbled together. |

|
The production codebase is your development branch. You write your development code in the production codebase, inside of an if block that turns it off. And you ship that development code to production as a matter of routine. |
|
So after making those leaps we were able to deploy more often. But new problems arose as we tried to dramatically increase speed. |

|
The story so far has been about actively destroying process and ceremony around deploys. But those were both cases of deciding to destroy process as a team. It’s another thing entirely for individuals to yolo their own destruction of process. One major reason that happens is because the deploy process can be too slow. |

|
If the deploy tooling isn’t made fast, there’s probably a faster and more dangerous way to do things and people will do that. They’ll replace running docker containers by hand. They’ll hand-edit files on the hosts. I want to stipulate that this doesn’t happen because people are evil, it happens because they’re people and they follow the path of least resistance. We want to make the “right way” to ship code also the laziest possible way. |

|
You also will occasionally need to deploy in a big hurry. Maybe you’re experiencing a SQL injection attack, or what have you. You don’t want to be trying to use a different set of fast deployment methods in a crisis. |

|
You want to be exercising the fast methods all of the time. That’s how you can know that it works. |

|
Do you really need to run that whitespace linter in critical path? Maybe you don’t. The compelling way to deploy should be the right way to deploy. |

|
Eventually we got fast deploys working reliably enough that people started to treat them as routine. But that also introduces some new problems. |
|
If we ship code very rarely, shipping code is a notable event. People will pay a lot of attention to it. |
|
On the other hand, if we ship code a bunch of times every single weekday, then shipping code is no longer special. This is all sounds very tautological. But it has implications. |

|
People will stand up from their desks and wander off while they’re deploying. They’ll go get coffee. They’ll go on a walk. The mountains will call them. |
|
It’s entirely possible to automate the whole deployment pipeline. In fact a lot of people think that that is what continuous deployment and/or delivery is. We didn’t do this, and in general I think it’s a bad idea. |

|
Let me give you the following analogy. A while ago Uber yolo’d a self-driving car trial in downtown San Francisco. It ended abruptly right after a video surfaced of one rolling right through a pedestrian intersection during a red light. |

|
It’s important to note that there was a human sitting in the driver’s seat, but that person didn’t intervene. Uber blamed that person for the incident. But that’s the wrong way to look at it. The automation was capable enough that the human’s attention very understandably lapsed, but not capable enough to replace the human. The human and the car are, together, the system. Things you do to automate the car affect the human. |

|
Automating deploys is often just like this. You can deploy the code safely, but you can’t accurately predict what it’ll do to the database. And so on. One must exercise good taste when it comes to automation. |

|
Make people actively press a button to deploy, even if 99% of your deploys are routine. Because in the rare case that something goes wrong, the human part of the system will be ready to react. Automation that only mostly works is often worse than no automation at all. |

|
Another problem we ran into as we ramped up to lots of deploys was that people skipped steps while deploying. |
|
If you deploy from a command line tool, this tends to be all of the context you have while you’re doing it. This is a popular choice these days, but I think this is a bad idea. |

|
That’s because you need to know what’s going on at the moment you’re deploying. You need to know what you’re pushing, if anyone else is trying to push at the same time, whether or not the site is currently on fire, and so on. |

|
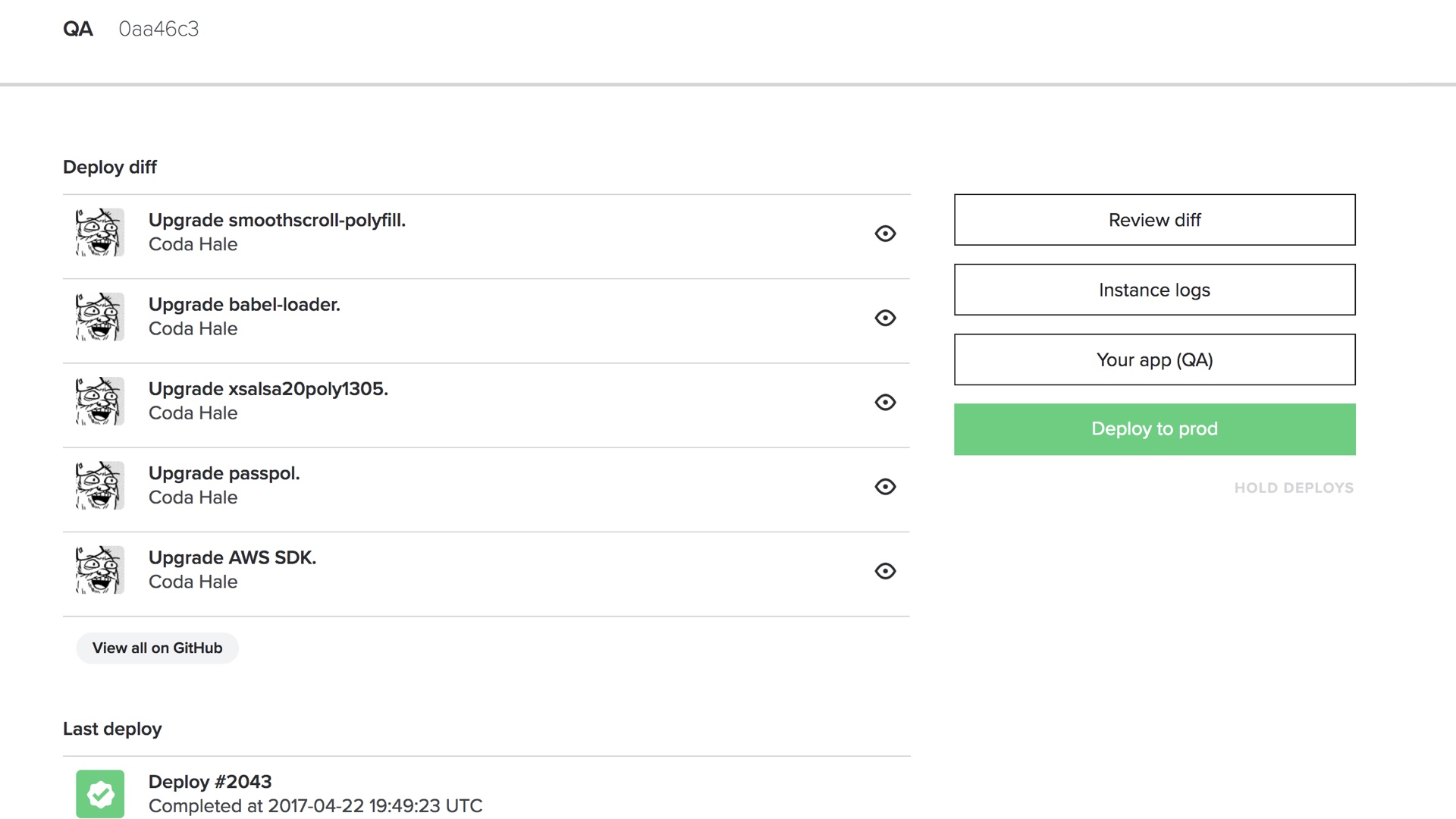
I get that we’re all nerds here and we love command line tools, but my unpopular opinion here is that you want a web cockpit. |
|
Web cockpits can surface all of that status to you in a digestible way, and they can lay out a workflow that comprises multiple steps. They’re also more accessible to people outside of engineering that might also want to deploy things. Which is great, because then you can build a culture where supportfolk can ship knowledge base changes, or designers can ship css changes. |

|
Another thing to keep in mind is that when we live in the world where shipping code isn’t special, that’s not just a problem for the people doing the deployments. It’s a problem for anyone that has to react to deploys. |
|
Releasing code at my first job was a nightmare in every respect. You’d show up on Saturday morning, and spend several days on it. It sucked. But one criticism you couldn’t make of this is that nobody knew it was happening. Brutality isn’t a great ethos, but it is at least an ethos. |

|
Deploying code once a year is one way to achieve awareness. But if we want to deploy every day, we have to get awareness on purpose. We have to intentionally build it. |
|
One thing you need is an easily accessible display of the deployment history, and the current status. You need to know what’s happening now, and what was deployed at any given time. |
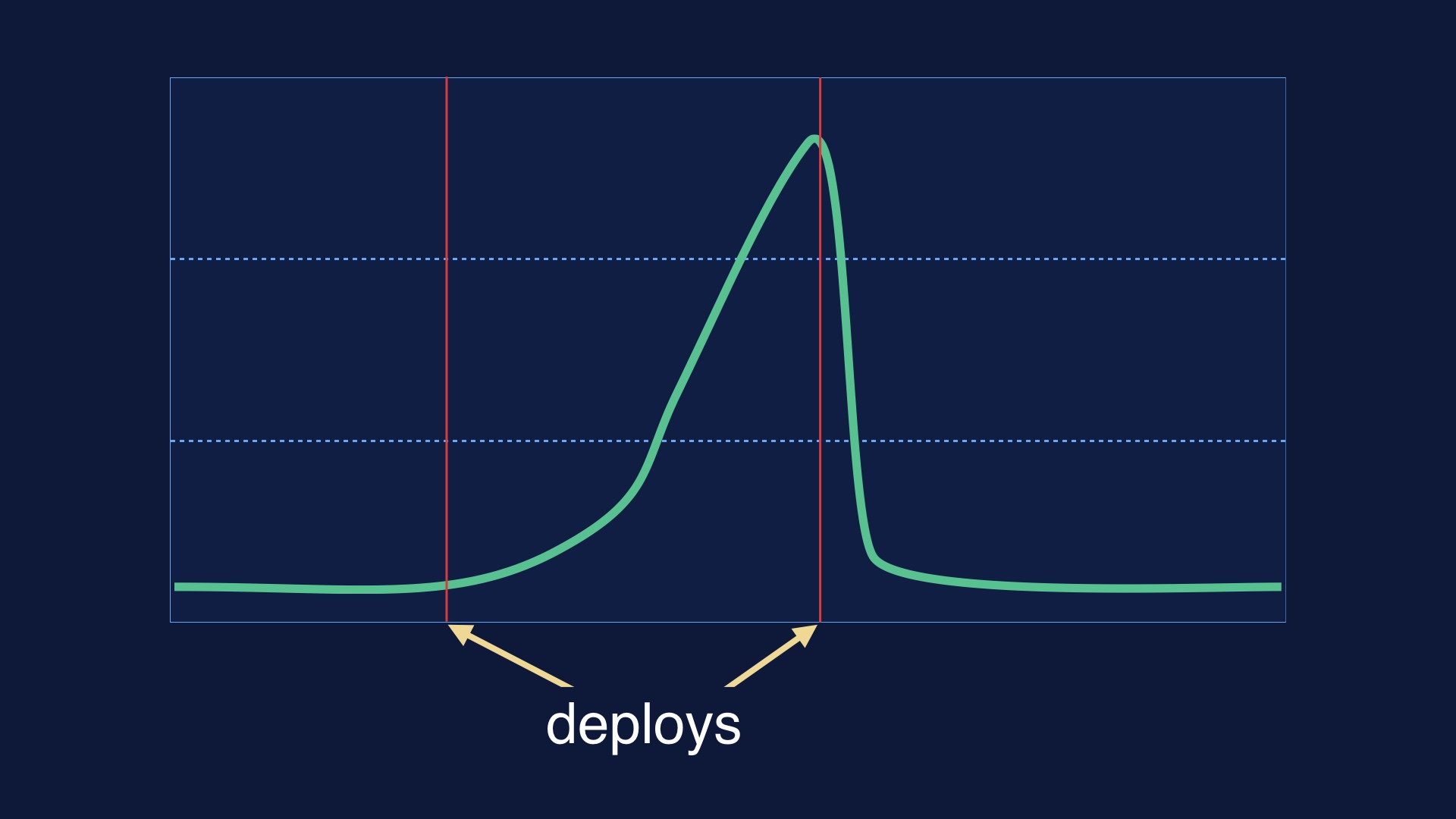
|
Automatically drawing deploy lines on all your graphs is also handy, so that you can correlate things happening in production to deploy times. |

|
Another thing that goes wrong here, which I’ve seen many other teams doing, is prematurely siloing all of their slack communications about pushes. |

|
What you get when you do this are incidents where a deploy by one team triggers alerts in the channel of some other team, who isn’t aware that a deploy just happened. You lose the obvious connection between the deploy notification and the alert if you do this. |

|
I think you should coordinate in one push channel, and push that as far as you possibly can. That gives you a shared sense of status. |
|
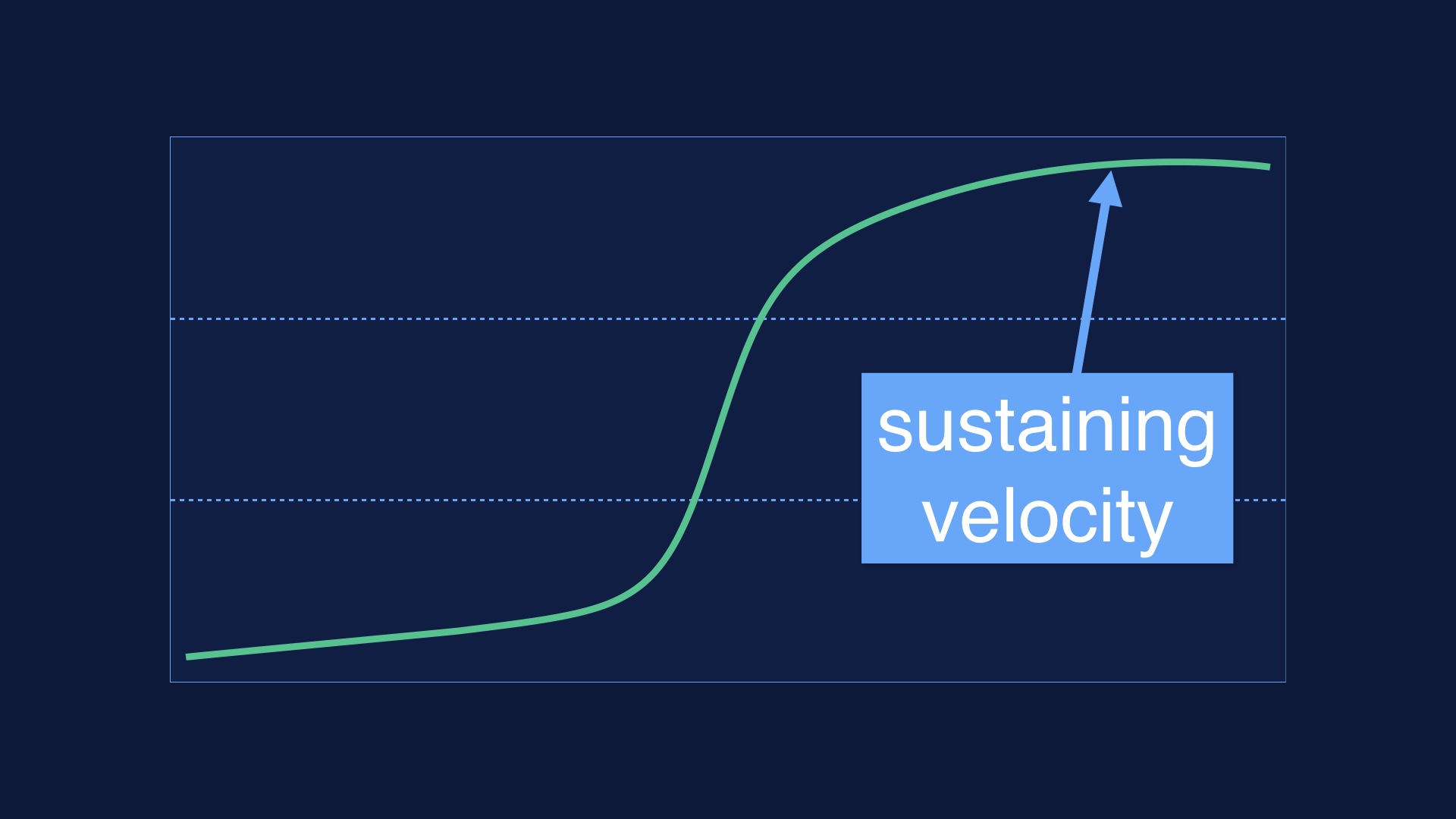
So those were some of the things that got us deploying safely and often. But eventually, overall developer velocity hits an upper bound. You can’t deploy faster, but your organization continues to grow. |

|
The returns on making deploys faster eventually diminish, and you can only fit so many end-to-end deploys in a day. Something has to give. |

|
One approach, which I definitely pursued for a while, is to make the day longer. Tech employees rise late in my experience, so you can get up at the crack of dawn and ship a bunch of stuff. That’s a bad solution though. |

|
We could split up deployables, but that’s taking on a great deal of operational debt. And comes with a lot of other baggage, which I’ll avoid ranting about. Suffice it to say I think we should try to exhaust other options before we do that. |

|
What we can do is try to find some common deployment patterns that are pretty safe, and figure out ways to extract them into faster pipelines. |
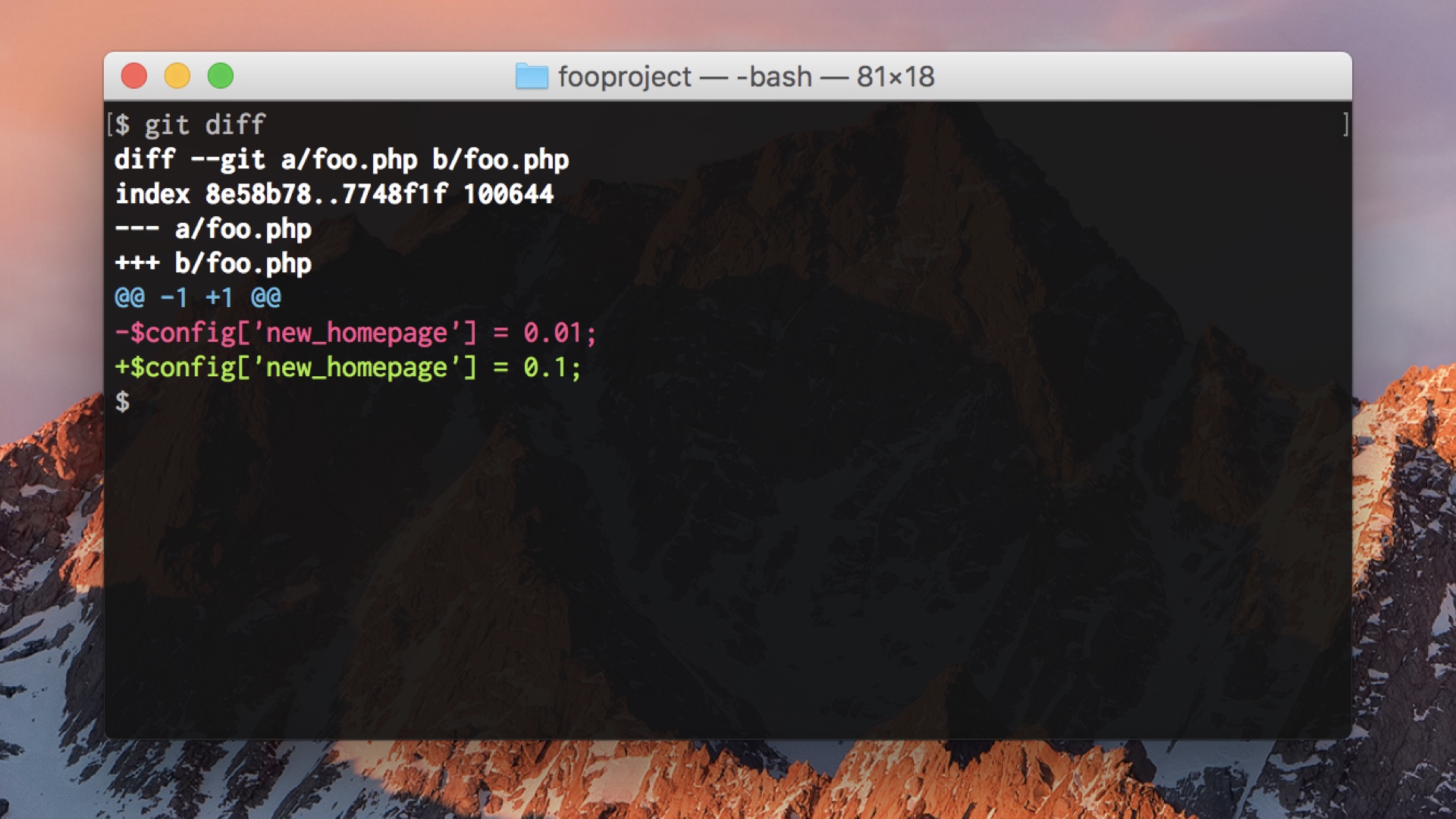
|
First one: if we’re doing flag-driven development right, many of the changes being made look like this. Just changing one config setting, turning things on or off or doing rampups. These are safe, or at least quickly reversible. We can take these and make a faster deploy lane for them that runs in parallel and skips the tests. |

|
Digging deeper, a lot of what you push if you are branching in code is code that isn’t executed in production. Conceptually, or even literally, you’re pushing code like this. These are really safe deploys, because the code is just dead weight that isn’t executed at all. |

|
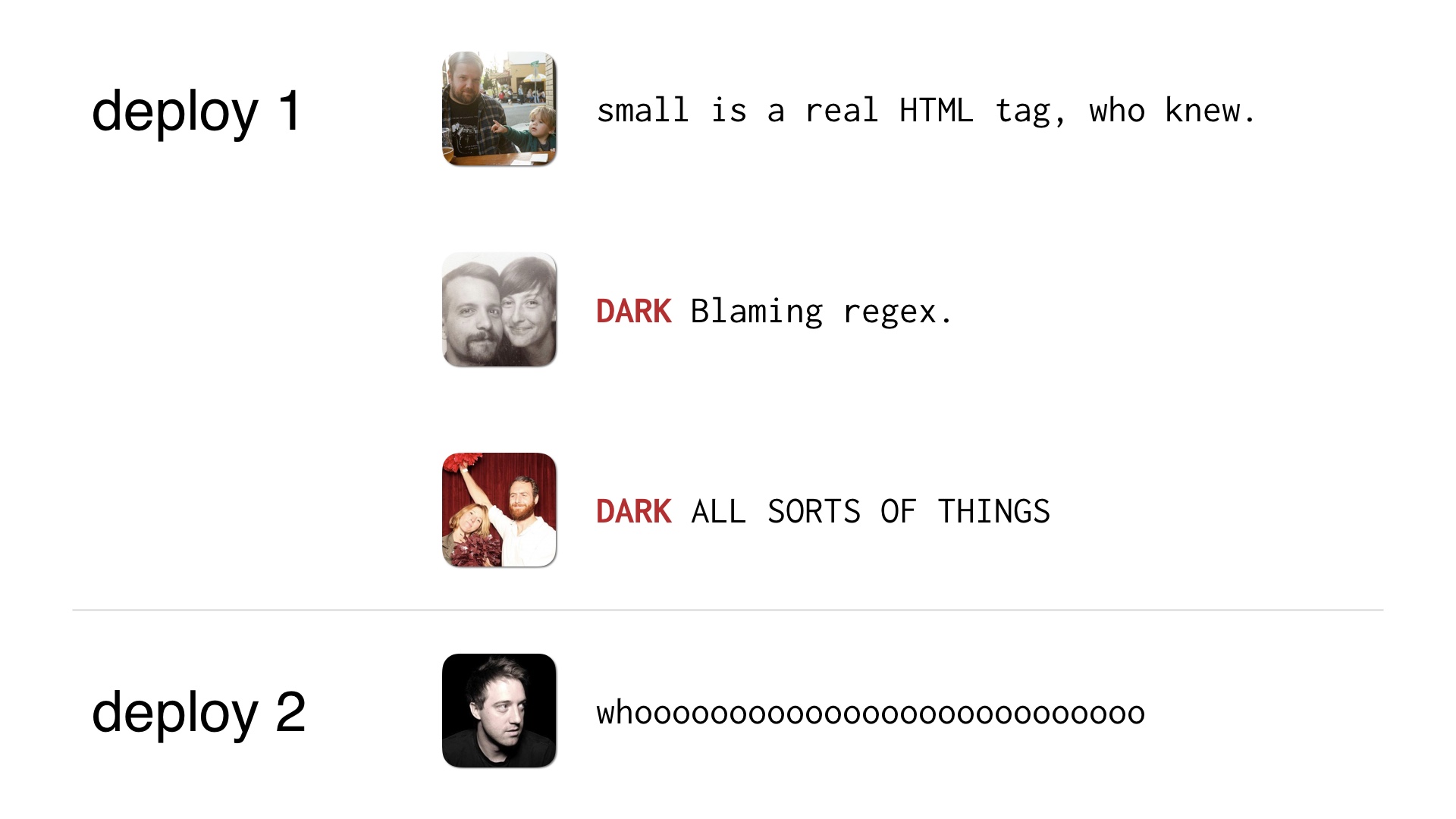
We can just invent a convention around that, where engineers can mark individual commits as being this pattern. What we did was just preface them with the word DARK in all caps. |
|
So in cases like this where you’d have four people trying to make changes, |
|
Maybe a few of them are DARK changes so you don’t need four deploys to ship them. The DARK deploys can just get shipped by the operator paying attention to his or her live changes. |

|
Those things help. But eventually those workarounds hit the same limits. So to keep sustaining your deployment velocity, you need to get folks cooperating. |

|
Ultimately you need to figure out how to do this safely. One deploy, with two people making live changes at the same time. This is the sort of thing that will often go fine with no coordination. But when something does break, these people need to be in communication. |

|
So we need a system for keeping those folks in touch. And that presents a real challenge. |
|
This is an example of a place where we did write a decent amount of code to solve a problem. We wrote a chatbot to help us coordinate. Someone was nice enough to port it to hubot. You can find it on npm now. |
|
We conceptually have a bunch of people at any given time that want to get some code out. As we noted before, they all gather in the push channel. |
|
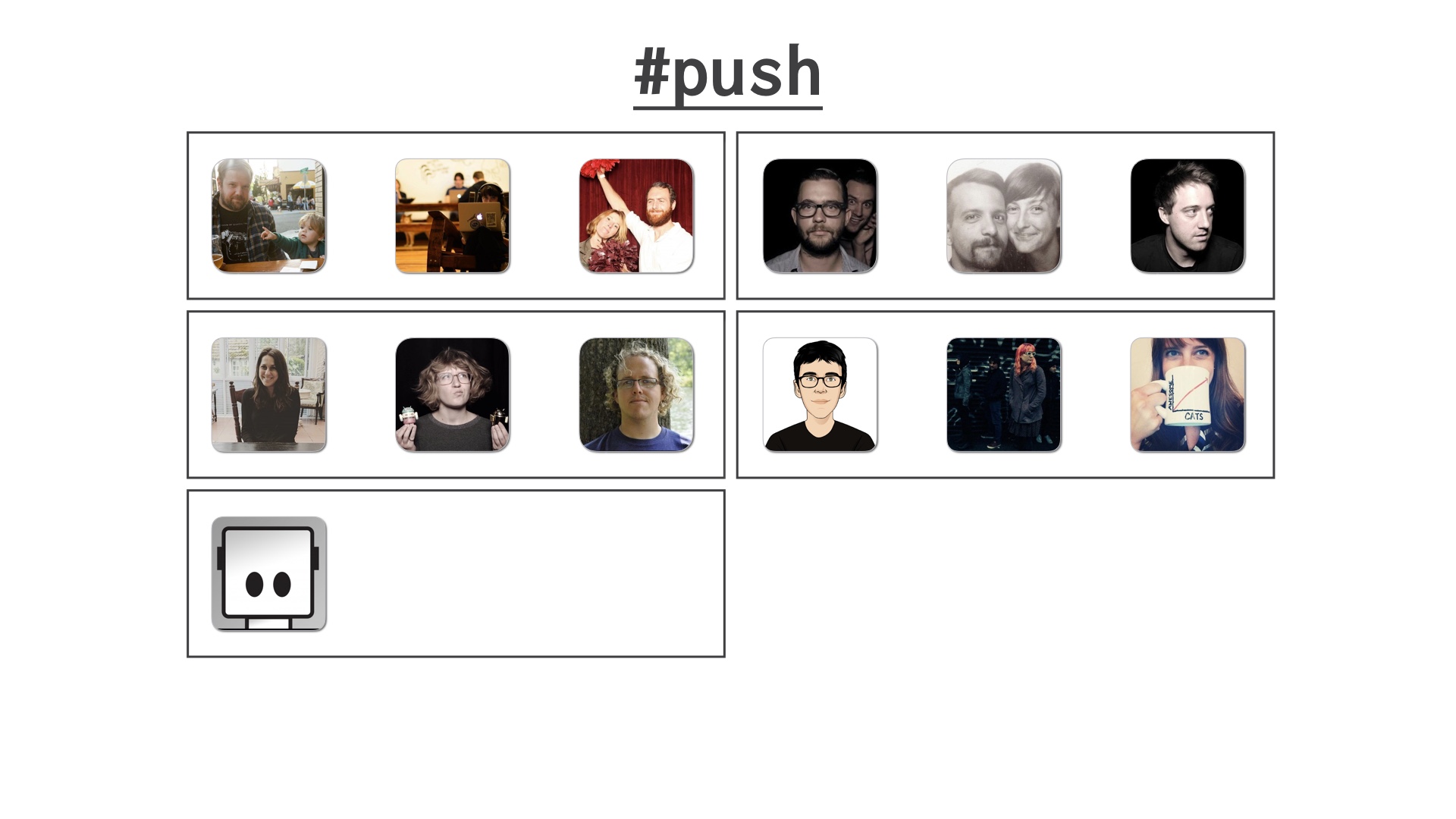
We decided to divide these up into train cars of an arbitrarily chosen size. I think the size changed over time but for the purposes of demonstration let’s say we pick three people at a time to deploy together. |
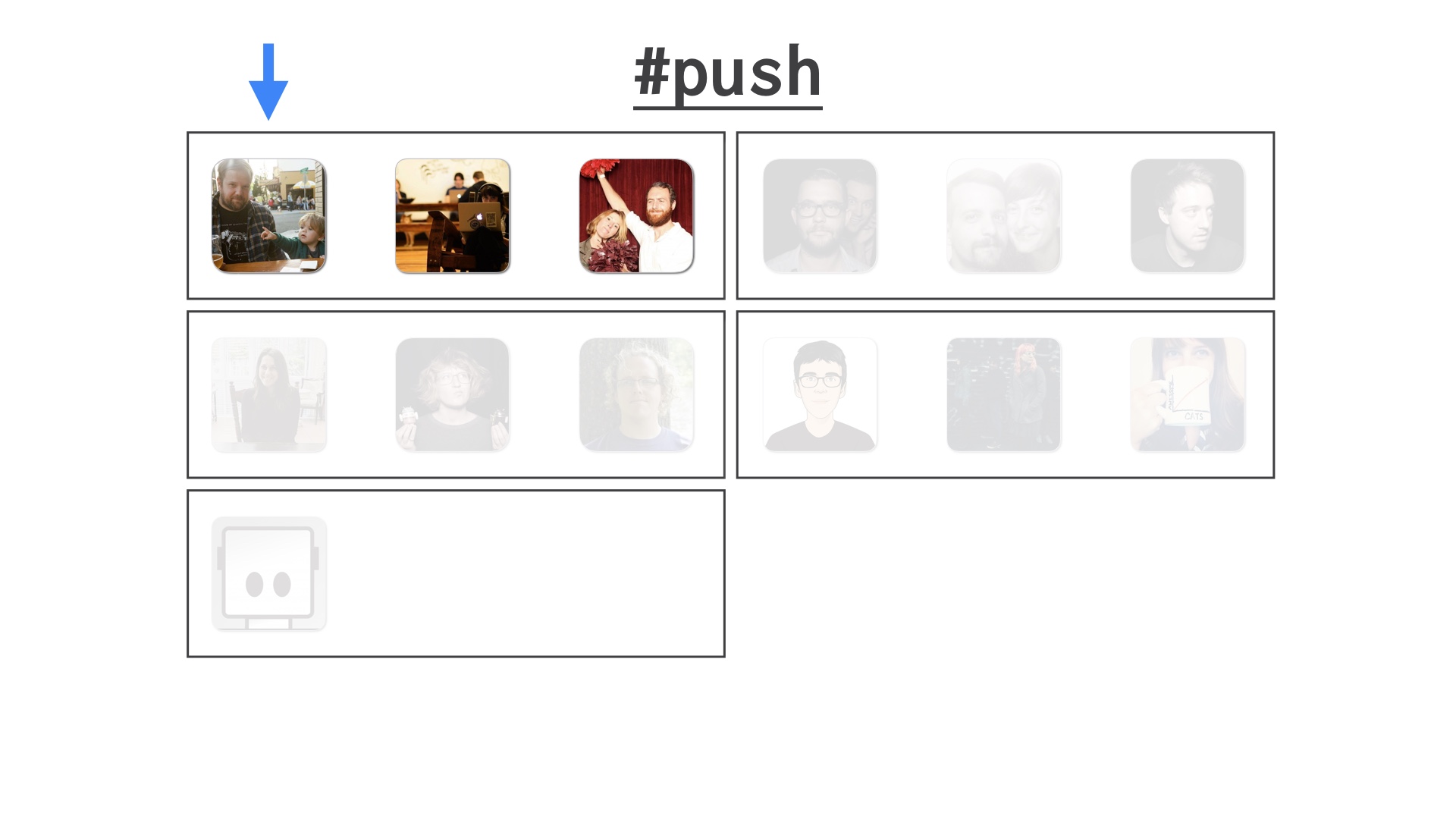
|
The train cars move through the queue one at a time. So the car at the head is deploying, the rest are waiting. |
|
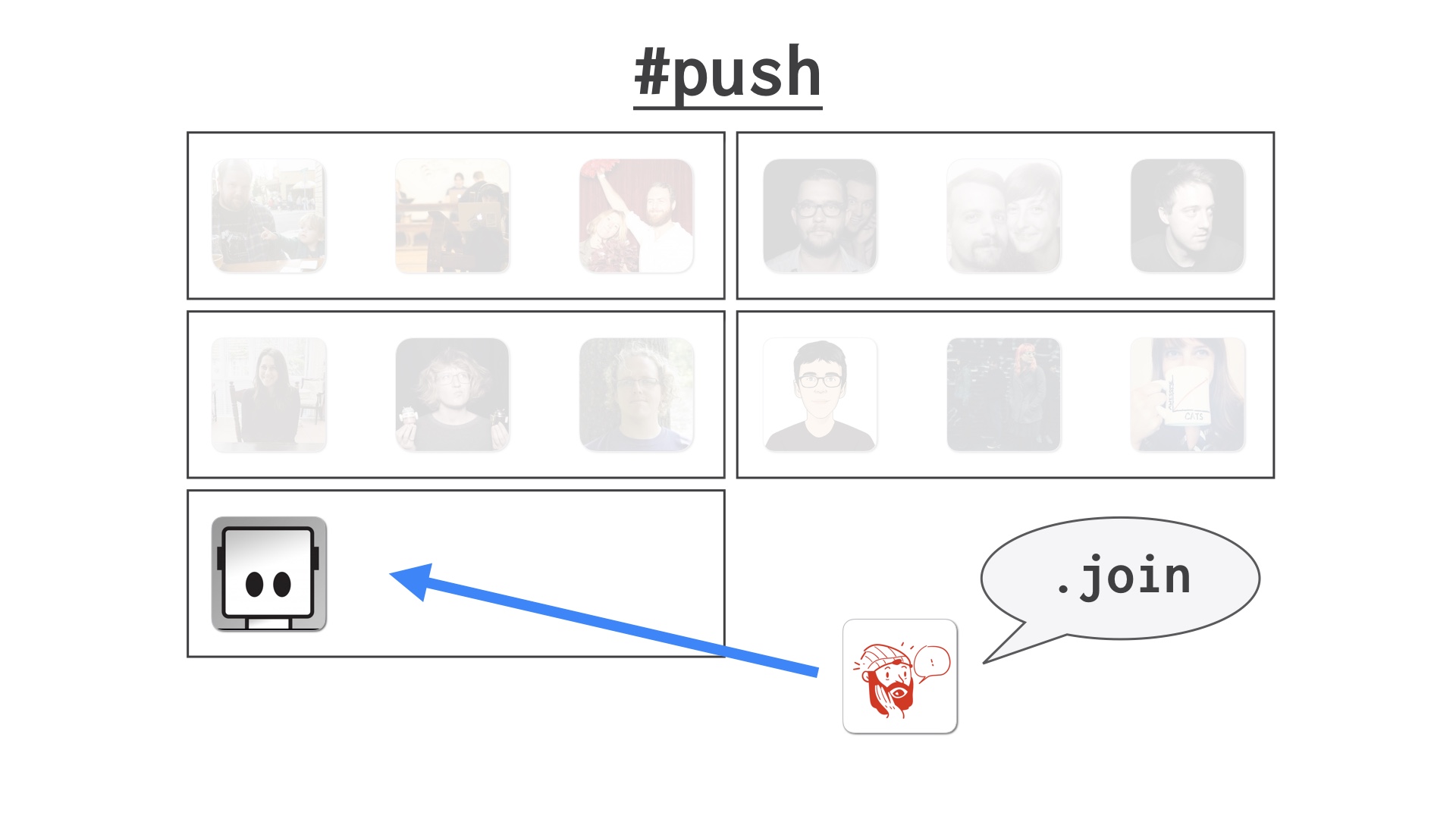
New people can hop into the channel and join at the back of the train. Or add new cars to it if the last one’s full. |

|
Within the first train car, the person at the head of the queue is designated the leader. By convention. This is the person that will be in charge of the deploy and will push all the buttons. |

|
The first thing the people do when the deploy starts is push their code. |

|
Then they all tell the bot that their code is in and they’re ready to go. Like this. |

|
Then the deploy leader pushes the button to deploy to staging. Or QA, if you’ve got QA, which we didn’t. But nevermind. |

|
Then the next thing the deploy team does is manually verify their changes. That might mean different things for each of them depending on what their changes were. |

|
When they’re done doing that, they signal to the bot that they’re done. When everyone is done the bot pings the deploy leader and tells them that the deploy is ready to move to the next step. |

|
Which is to deploy to prod. |

|
That’s how it goes in the best case. But things can go wrong. Someone can also tell the bot that something’s wrong, and the bot will stop the train. |
|
If that happens, since we coordinate in one channel, a lot of folks are in some state of paying attention and are available to help. |

|
Ok, so these are some of the main social hacks that got us somewhere north of 100 engineers on a single repo. |

|
I wanted to give a sense for what it feels like to evolve alongside a continuous delivery effort. I don’t think you should take this as a set of instructions per se. It’s a toolbox you can use, but the details of your situation will differ. |

|
If you’re building a Mars rover, for example, the failure tolerances you have and the tradeoffs you will want make will be different than ours were. |

|
It’s notable that almost all of the hard things we dealt with were social problems. Some of these solutions involved writing code, but the hard part was the human organization. The hard part was maintaining a sense of community ownership over the state of the whole system. |
|
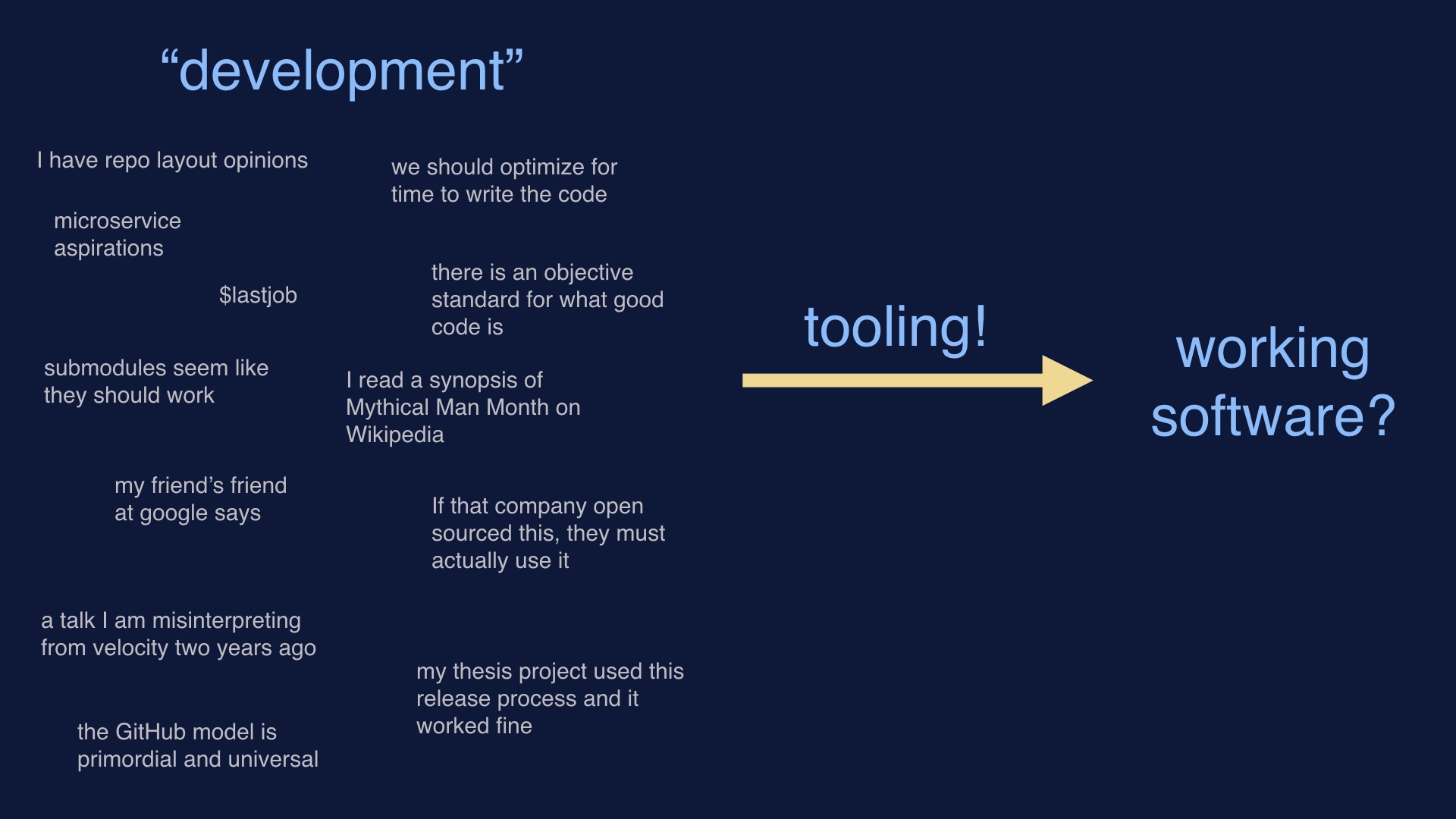
Since in order to deploy software we have to write it first, we tend to start with things that make software easiest to write. Or the specific load of development baggage that we’re most comfortable with. Then we hope that we can bang on some tooling and get working software in the end. There’s no reason to expect that this approach should work, or result in anything good. |
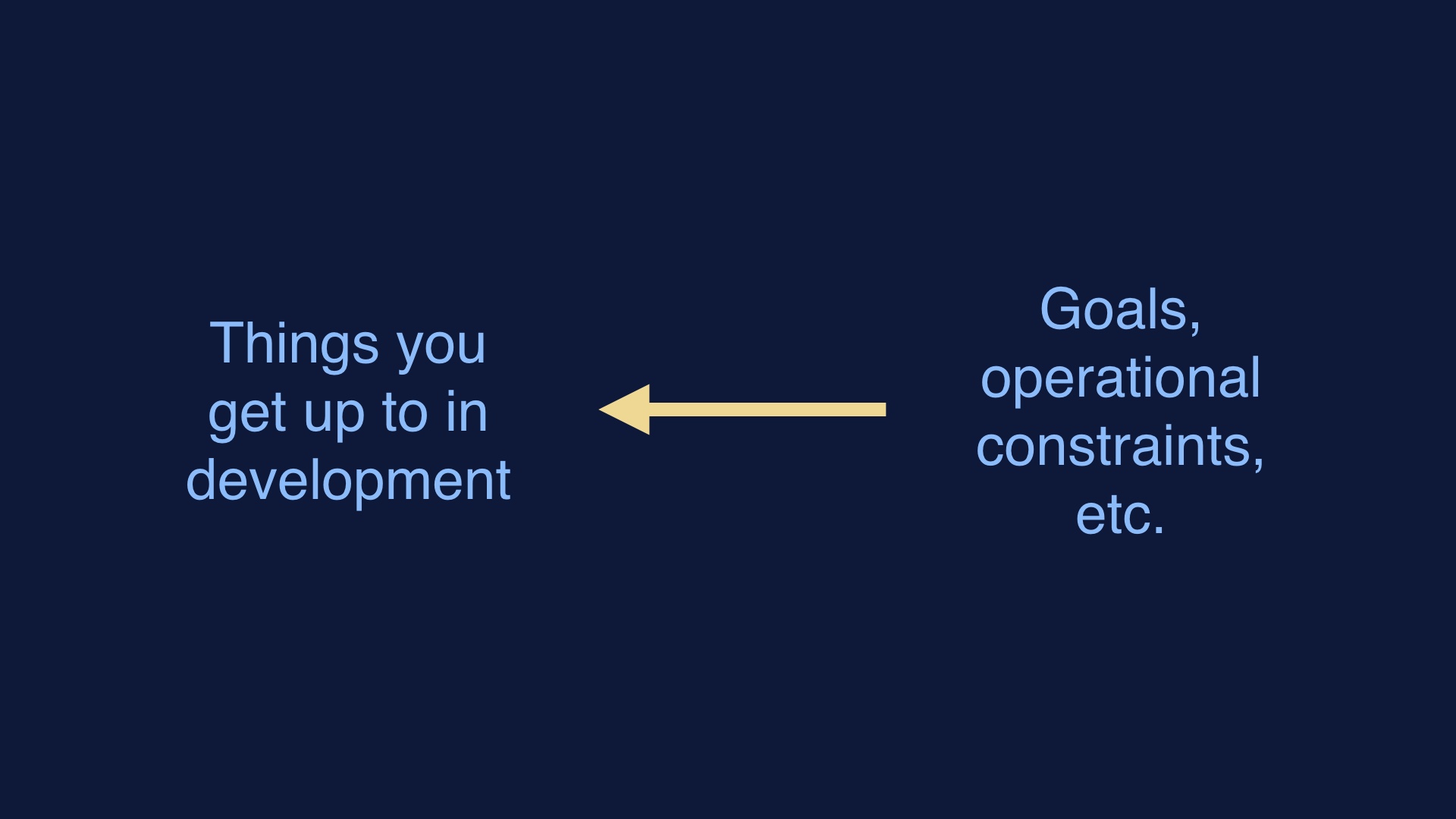
|
This is the approach that does work. Consider what your goals are, and what operates in production. Then work backwards from those things to the methods that you use. |

|
If you’re trying to increase developer velocity and it looks like the problem is interesting technically, you might want to stop and ask yourself if you’re in the weeds. The tendency once you’ve programmed yourself into a serious hole is to keep programming. Maybe you should stop trying to program your way out of difficult situations. |

|
fin |